Winning 3rd place at MLOPS LLM Hackathon: Question & Answer for MLOps System
Table of Contents
This post describes the experience of team RedisCovering LLMs, as we developed a Question & Answer system specialized on MLOps community slack discussions, armed with GPT-3.5 for precise answers and verifiable references to slack threads, guarding against misinformation.
1. Introduction
Last weekend, I had the opportunity to participate in a 12-hour hackathon organized by the San Francisco Bay Area MLOps Community. It was my third hackathon experience, and the first one I attended through the MLOps Community. The hackathon took place at a modern office lounge in San Francisco and started at 9:00 AM on Saturday, June 3rd. We were all competing for prizes of up to $1500. (Only first place in each track was awarded prize money 😭)
During the hackathon, I created a team called RedisCovering LLMs, consisting of myself, Rohan Potdar, Atif Tahir, and Oliver Carmont. Each team member played an important role in our project related to answering MLOps and other ML/DS/AI questions that community members may have.
Objective of LLM Hackathon
Our objective was to build a system using Redis, Relevance AI, and Open AI embeddings. We were given a starter kit that included sample code for connecting to the Redis vector database and using Open AI embeddings, as well as code samples for connecting Redis and Relevance AI through their APIs. There were two tracks in the hackathon:
- Building a question-answer system using Slack conversations as a knowledge base
- Generating community insights using the same dataset
We chose to build an LLM-powered application to answer MLOps questions for community members 😊
Architecture

Team Contributions
Alejandro
Vector Search
The work that I primarily contributed to was the LLM pipeline for Question and Answers. This consisted of using a Redis index, essentially a data structure containing the MLOps Slack corpus, represented as a set of geometric vector embeddings, in order to associate two sentences as being semantically the same.
search_step = RedisSearch(
index="mlopscommunity",
query="{{params.question}}",
vector_field="vector",
model="text-embedding-ada-002",
page_size=int(input.knn_size),
)
The way I like to think of this data structure, is that it is similar to a B-Tree, except the partitioning is done by segregating disjoint subspaces within the embedding vector space. The reason for this, is that this embedding data is represented in the program’s memory (i.e. Redis internally), so it helps to have spatial locality. A little bit of math goes a long way!
In other words, you’re often doing comparisons of embeddings that are geometrically close to one another, so why not have them nearby to one-another. See my post about Vector Spaces here to help paint this picture a bit more clear. Anyways, Walmart has a pretty juicy blog post about this, where they describe an internal library they created for vector search, if you would like more details.
Creating Citations
We didn’t do anything too special with the prompting, a lot of it was handled by the Relavence AI and OpenAI API’s. It’s cool how you can inject any text into a prompt, and the LLM uses that as a conditioned context in order to make a prediction of what comes next!
llm_qa = PromptCompletion(
prompt="Context:{{steps.redis_search.output.results[*].message}}\nBased on the above context answer the question.Question:{{params.question}}\nAnswer:",
)
chain.add(llm_qa)
The cool thing about doing the vector search, is that under the hood it performs Approximate K-Nearest neighbors to compute how close vector embeddings are to one another. Since a user queries a question, we know that all the outputs of this vector search basically amount to citations. The reason this is important, is because Large Language Models are not deterministic and often hallucinate answers. So, it was critical for us to know that users were provided with meaningful context on why an answer was generated in the way it was.
res = chain.run({"question": input.question}, full_response=True)
summary_response = res["output"]["answer"]
citations: dict[str, str] = [
{"id": v["id"], "message": v["message"]}
for v in res["state"]["steps"]["redis_search"]["output"]["results"]
]
Results
Take a look at a spreadsheet we submitted, containing question and answer outputs.
Screen Capture
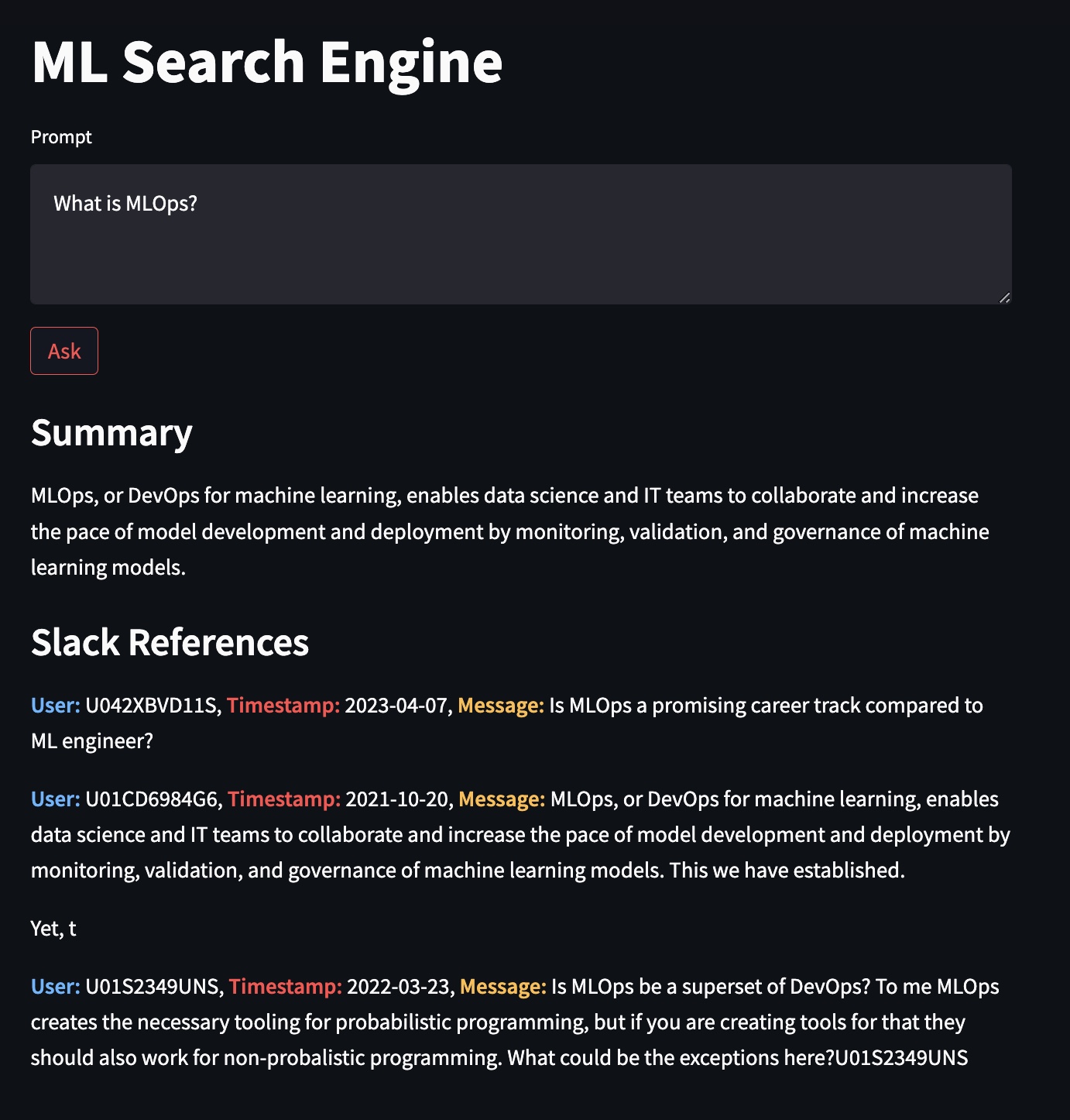
Figure 2: Querying ‘What is MLOPS’ to ChatBot.
Video Demo
Conclusion
Overall, the hackathon was a fantastic experience, and I’m grateful for the opportunity to work with such a talented team. Thank you to our judges Chip Huyen, Daniel Svonava, Sam Partee, and Jacky Koh. One of the judges, I can’t say which, told me it was so difficult choosing a winner in our track. With that said, I’m proud we were even selected to present in front of the esteemed judges, let alone going home with 3rd place. It was a great way to contribute to the MLOps community and explore new ideas and technologies. I look forward to future hackathons and continuing to build upon the success of this project!