Getting Started with PyFlink: My Local Development Experience
Table of Contents

Background
A hobby project I am working on, involves developing streaming workloads. We want to process realtime data and support traffic prediction! Often at the start of tool adoption and especially when working in a multi-tool ecosystem, I was finding myself at a familiar roadblock:
As the engineer responsible for creating the streaming workloads, I was having a hard time weighing the tradeoffs in what language to use for our data pipeline’s tooling. Though I have little experience in Java, I had gotten a minimal example of processing events using Flink with the Java SDK. The thing is, I am already writing Terraform code, writing Dockerfiles and using Python libraries to analyze traffic data.
I was having a hard time accepting the cognitive strain it would put on me because there is a lot of resources detailing Flink’s Java SDK on the web. However, the same could not be said for PyFlink. Furthermore, I had to assume the Python SDK, which contained a subset of the Flink API, may not be sufficient for our use case. As a budding Data Engineer, I didn’t the severity that being wrong could have on delaying development. Either way, this project was about taking risks and here’s me sharing my experience with that.
Running the 1-word_count.py Hello World of PyFlink
My first instinct when learning something new is to try some toy examples. So, I wanted to create a Hello World application with Pyflink. Yet, I did not even know what I didn’t know! Usually I google lots of blog posts, but not many were coming up. So a quick github search and I found myself at the following repository.
Inside, I found various examples illustrating the capabilities of the Python SDK. As of writing, the latest stable release of Pyflink is at (1.18.0), yet the examples depended on PyFlink (1.13.0). So, things were a bit outdated, but that’s alright.
Quick Background into Flink
Just to give some context, Flink was created for distributed data processing tasks. The creators set on an architecture that involves:
- Job Manager
- Task Manager
So the Job Manager acts as a leader node in the system, receiving the Job Graph from the Job Client and converting it into an execution graph with multiple tasks. Then, the execution graph, which is a logical representation of the distributed execution, has all its operators converted and parallelized for execution on different Task Managers.
Does that sound fair? Users request data processing jobs to the Job Manager, who is in charge of translating that into logically parallel tasks. Afterwards, Job manager speaks to Task manager and makes sure it gets completed 😄
Lets get into business!!
Seeing is Understanding: The TaskManager Metrics Were Missing
The repository uses Docker, which integrates with Docker Compose. Immediately, the Flink Dashboard did not display the metrics located with either node. I decided to look further into this, so that I would be able to debug my PyFlink Programs.
Since Docker uses a virtual network to enable communication between Docker containers, I checked if the JobManager Container address, found in the Task Manager’s configuration, was identical to the Docker-Compose container_name field. The reason for this, is because Docker’s virtual network uses a built-in DNS server. What that means is, that containers don’t need to know eachother’s IP Addresses ahead of time, they just use an alias that is resolved. Hence, I changed the configuration to the following:
jobmanager.rpc.address: jobmanager
The configuration file that Flink uses for the Job Manager and Task Manager containers is found in /opt/flink/conf/flink-conf.yaml path inside of the docker image.
Confirming that my Docker Containers were in the Same Network
Using docker inspect on my Network, I looked for the ["Containers"]["Name"] field in the following output:
"Name": "playgrounds_default",
"Id": "053576ce2329df463c79e31098a0bc64b6eccee2f2ed5d14616807200b7c5320",
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.28.0.0/16",
"Gateway": "172.28.0.1"
}
],
"Containers": {
"18ad8caa90245abab938e02a3ae972a6e5b8c9126c8a19085ebbb4e793e52d19": {
"Name": "playgrounds_jobmanager_1",
"EndpointID": "3cefc52020c1c1ffa3a9af5b7db7f1934985bf5b4f0a4b6a075d682c5ed8e749",
"MacAddress": "02:42:ac:1c:00:03",
"IPv4Address": "172.28.0.3/16",
"IPv6Address": ""
}, "1c54382e9be6bd2c0c72c6f4d11cb79c930050f97d75f877c7035d9c50cf8c19": {
"Name": "playgrounds_taskmanager_1",
"EndpointID": "4c5c3c08020cfe16f27f8fd75ff91c6d7262c448dad208225b2f2d6320de55e8",
"MacAddress": "02:42:ac:1c:00:04",
"IPv4Address": "172.28.0.4/16",
"IPv6Address": ""
}
}
The Docker Compose manifest seemed to be working correctly. I mean right? I see both of the containers in the json payload. So, I still found it strange that information was not being logged from the task manager to the job manager. Maybe it had to do with a port not being accessible?
Confirming that my Docker-Compose Exposed the Correct Ports
It turns out that communication between the JobManager and the TaskManager is facilitated through a special port.
So, I made a sanity check to see if the correct ports were accessible. I confirmed the firewall rules have the 6123 port open in the Docker Compose file.
hostname: "jobmanager"
expose:
- "6123"
That didn’t do the job either. So I had to dig a bit deeper.
Logging Was at Fault: Changing Configurations
Finally, it occurred to me that it may be a logging issue. So I took a look and discovered that Log4j, a Java-based logging utility, was not being able to find a configuration file named log4j-console.properties, so I created it and populated the file with the following:
# Root logger option
log4j.rootLogger=INFO, stdout
# Direct log messages to stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
Victory! For now…
Finally some progress 😅
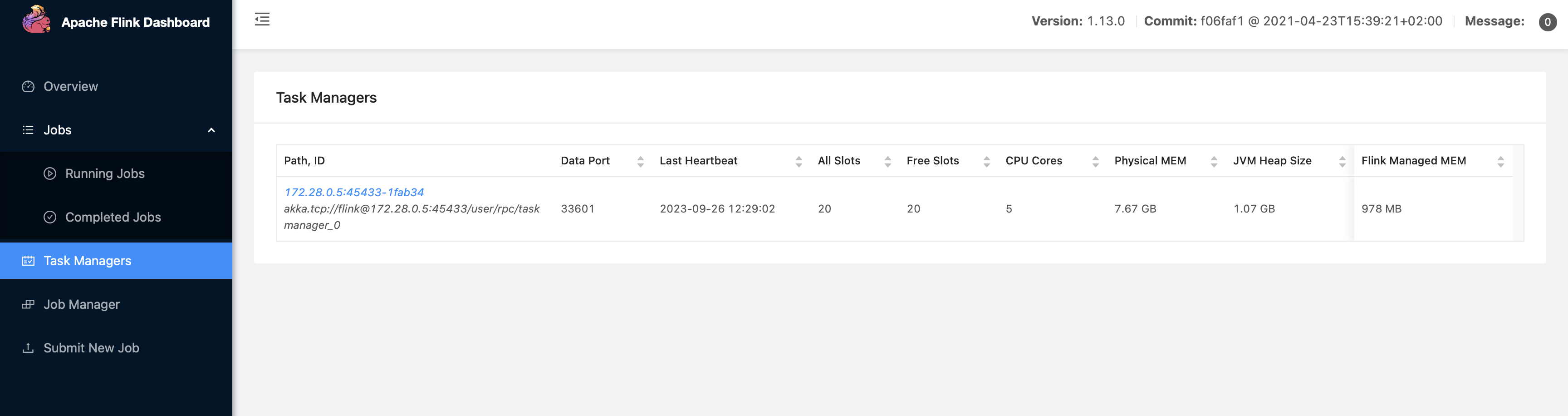
Here we can see that we have about 8GBs of physical memory, with 1GB being dedicated to the JVM Heap Size and 978 being dedicated to the Flink managed memory.
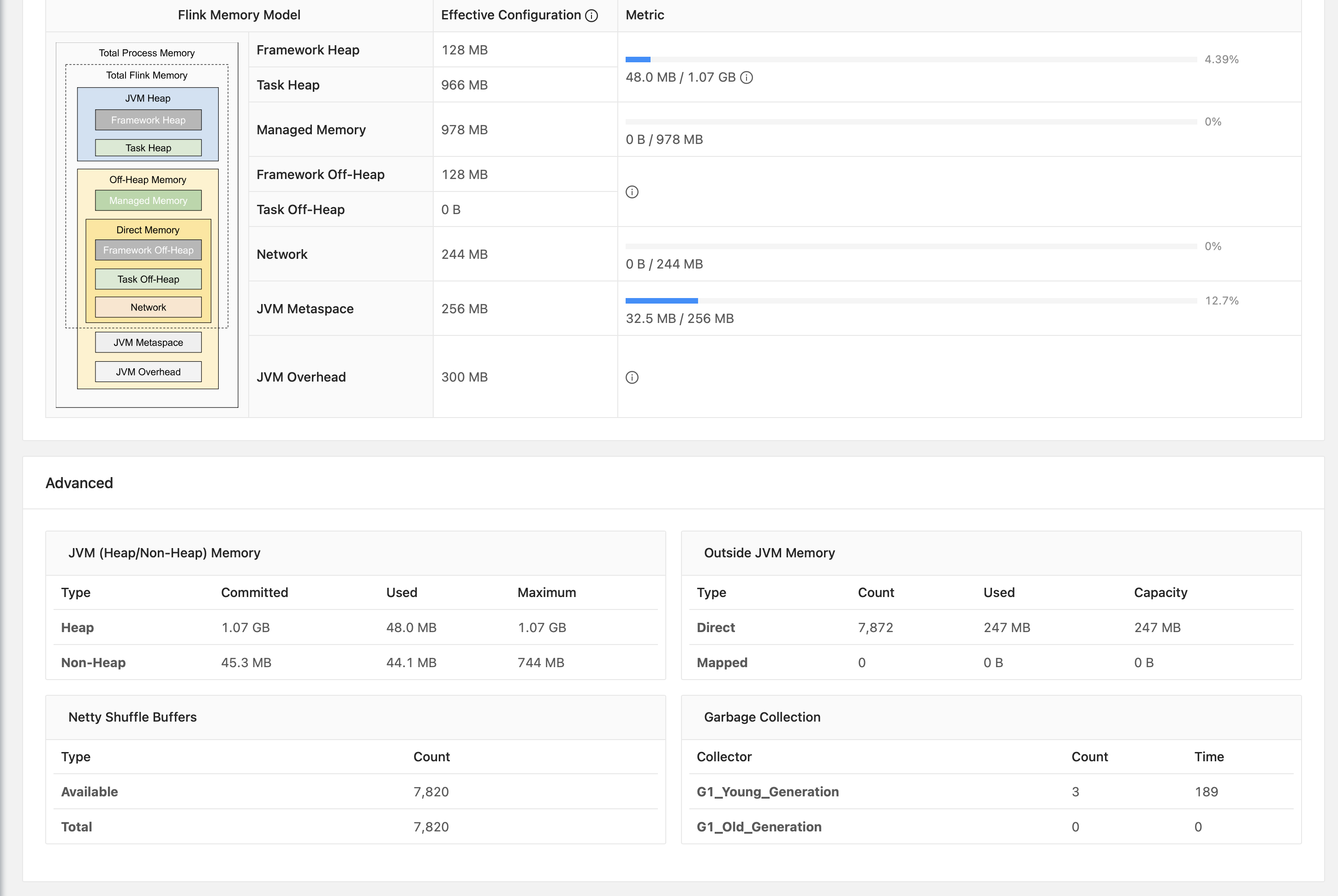
This gave me the confidence to understand the behavior of my PyFlink Jobs!!
Switching to a Recent Release of PyFlink
Now that I got Pyflink working on the pyflink/playgrounds:1.13.0-rc2 Docker image, I decided it was time to move over to a more recent release of Pyflink. I ended up using flink:1.16.1-scala_2.12-java8, however I wasn’t aware of the additional dependencies I would have to install.
Almost immediately, I was not able to run one of the Pyflink examples:
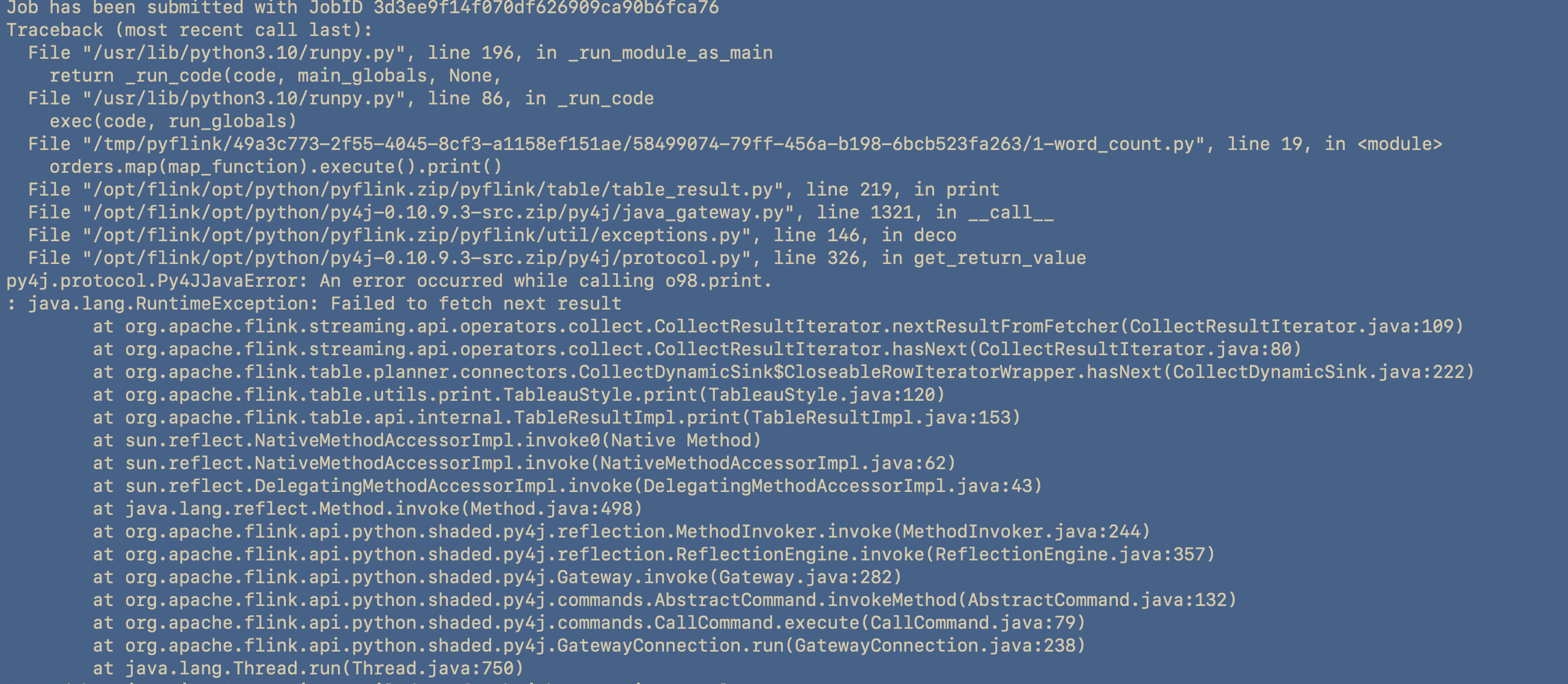
The further I scrolled down, the more the culprit showed itself:
The error in question was arising from the PyFlink dependency named Py4J.
What Flink has to do with Py4J
Py4J is a bridge between Python and Java, and it enables Python programs to interact with Java objects. PyFlink heavily relies on Py4J for its operations. This error indicates that there was an issue while calling the Java method o98.print
I knew there were several possible diagnoses. It could come down to memory issues, networking issues or version incompatibilities.
In Search of Endless Dependencies
Considering the Jobmanager had trouble accepting the script, I ventured into debugging the JobManager’s docker container dependencies. On the Jobmanager, it appeared, that in fact, I did not have one of the dependencies:
% docker-compose exec jobmanager pip show apache-flink
WARNING: Package(s) not found: apache-flink
Now when I tried installing this dependency, one of its other dependencies pemja was failing: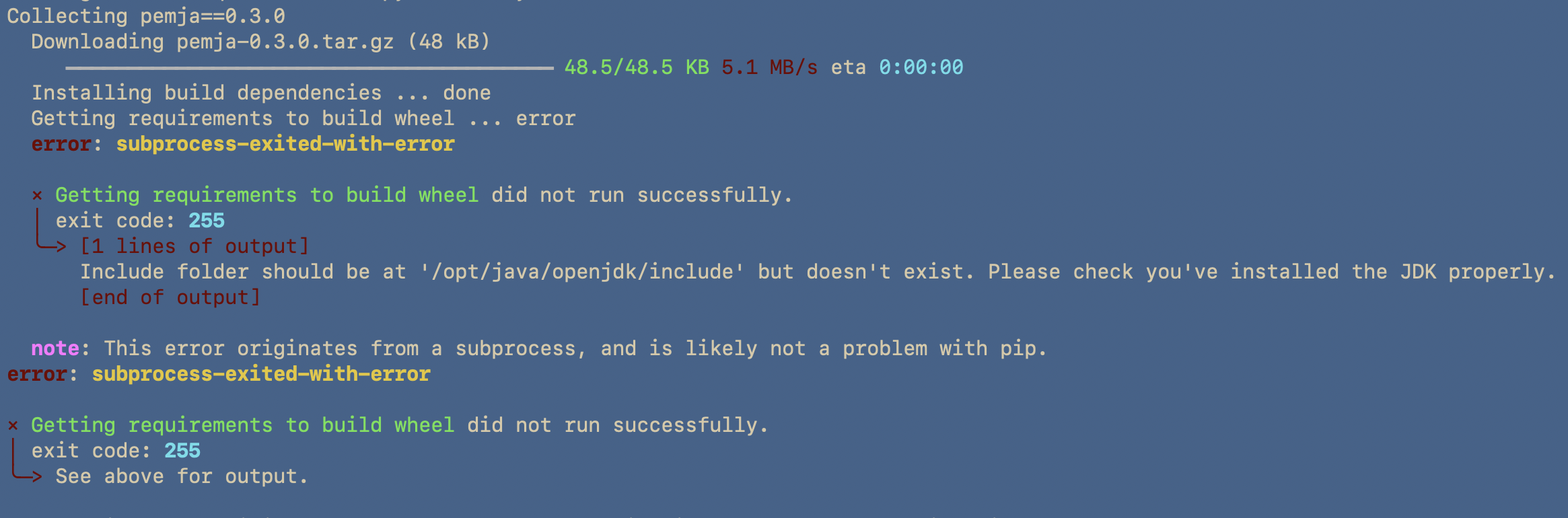
Now I found this strange, because I did have Java installed. In fact, here is the demonstration of that:
(base) alejandro@Voyager playgrounds % docker-compose exec jobmanager java -version
openjdk version "1.8.0_362"
OpenJDK Runtime Environment (Temurin)(build 1.8.0_362-b09)
OpenJDK 64-Bit Server VM (Temurin)(build 25.362-b09, mixed mode)
(base) alejandro@Voyager playgrounds % docker-compose exec jobmanager echo $JAVA_HOME
/Library/Java/JavaVirtualMachines/jdk-1.8.jdk/Contents/Home
Pemja Depends on JDK: But I thought I had JRE installed??
It turns out the dependency of Pemja relies on the JAVA_HOME environment variable being set. I did have it set, but I was still having issues.
It appeared that I had to do some more understanding of the Java Programming language to find the root cause of this problem. More specifically understanding the difference between the JDK (Java Development Kit) and the JRE (Java Runtime Environment).
What is the Java Runtime Environment?
The Java Runtime Environment (JRE) is an implementation of the Java Virtual Machine (JVM). This is used to interpret compiled Java Binary Code (bytecode) for the computer to execute. On the other hand, JDK provides a comprehesnive set of development tools just as the compiler (javac), an archiver (jar), and a documentation generator.
The reason Pemja relies on the JAVA_HOME variable, is because is searching an include directory contains header files that are used when compiling native code to interface with Java code (via the Java Native Interface, or JNI).
The quick fix was installing JDK:
apt-get install -y openjdk-11-jdk
Apache Flink Python Package not being found
Now this brings us to the Python intepreter side of things. First you must understand that Pyflink uses the python interpreter when:
- Submitting the Python jobs via
flink run - Compiling Java/Scala jobs containing Python UDFs.
This was the following error:
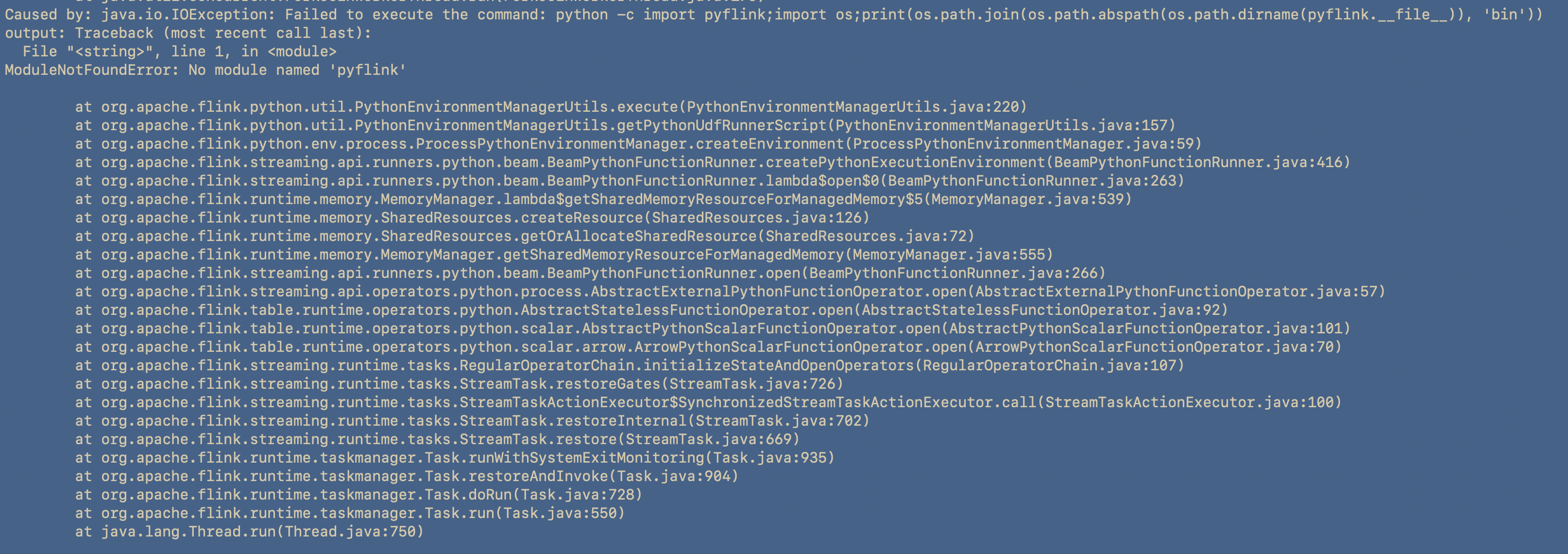
Caused by: java.io.IOException: Failed to execute the command: python -c import pyflink;import os;print(os.path.join(os.path.abspath(os.path.dirname(pyflink.__file__)), 'bin'))
output: Traceback (most recent call last):
File "<string>", line 1, in <module>
ModuleNotFoundError: No module named 'pyflink'
Python uses the PYTHONPATH environment variable to determine where to look for modules, I used the interactive python shell and tried the following:
import pyflink
This import statement works, therefore pyflink is accessible from the Python interpreter used by Flink. Furthermore, the PYFLINK_CLIENT_EXECUTABLE has been set to /usr/bin/python, but the issue still persisted. This suggests that flink is in a different environment.
Lo and behold, it turns out the python interpreter could not access the pyflink module in the taskmanager container. What I didn’t tell you, was that I was debugging everything in the jobmanager docker container. Therefore, I rebuilt the Task manager and this brought me to the next problem with the Python Interpreter:
Apache Beam 2.38 does not support Python 3.10
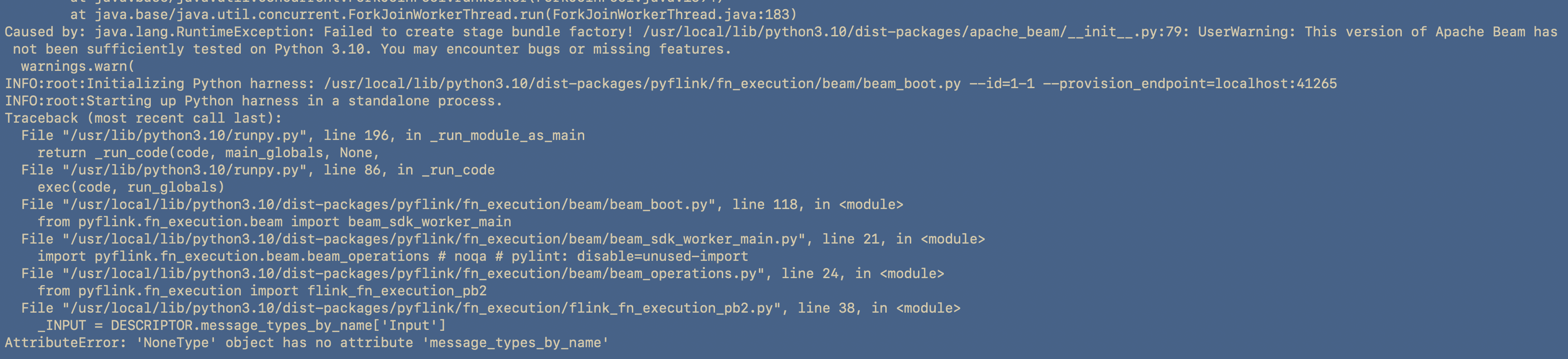
This is the current way we installed Python 3.10 in our dockerfile:
RUN set -ex; \
apt-get update; \
apt-get -y install python3; \
apt-get -y install python3-pip; \
apt-get -y install python3-dev; \
ln -s /usr/bin/python3 /usr/bin/python
So our option is to either downgrade our python version, or to upgrade our beam to support 3.10. So to upgrade Beam, I decided to use an even more up to date Pyflink docker container flink:1.17.1-scala_2.12-java8 and install its version of the Python SDK.
apache-flink = "^1.17.1"
Success!
At long last, I can run the simplest of examples. To me it was cool to sift through so many levels of abstraction and finally get using one of the big boy Data Engineering tools 😆
% docker-compose exec jobmanager ./bin/flink run -py /opt/examples/table/1-word_count.py
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.flink.api.java.ClosureCleaner (file:/opt/flink/lib/flink-dist-1.17.1.jar) to field java.lang.String.value
WARNING: Please consider reporting this to the maintainers of org.apache.flink.api.java.ClosureCleaner
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Job has been submitted with JobID 9265f8b39d40b298deb67046d8894c9d
+--------------------------------+----------------------+
| name | revenue |
+--------------------------------+----------------------+
| Jack | 100 |
| Rose | 300 |
| Jack | 200 |
+--------------------------------+----------------------+
3 rows in set
Lessons Learned
If a docker image doesn’t ship with Python 3.10, then theres a likelihood that the software isn’t compatible with 3.10
Do not try to fit a Triangle in a Square!!